Unicode?
Yes, Unicode.
Unicode is a text-encoding standard used in virtually every web and desktop application in the world. It is responsible for encoding text written in just about every language and character set. In fact, you are reading Unicode right now.
I believe that all developers who deal with text have a responsibility to understand the concepts of Unicode. Unicode knowledge should be required by all web developers, database designers, back-end developers... well, everyone. The requirement to process text is ubiquitous for nearly every program, so every programmer needs to know how to do it correctly.
Honestly, I'm surprised by how little Unicode is emphasized in schools and elsewhere. At my college, we were basically taught to assume that foreign languages don't exist (i.e. ASCII only). I don't know if it's because they were unaware of Unicode, or if they wanted to "simplify" the material. Everyone else just seems to forget that Unicode exists.
For those of us who know what Unicode is, we know it's not simple. There's a lot to know, and it's still incredibly easy to make mistakes. I hope this list of gotchas will help somebody.
Gotchas
Characters that appear the same might not test equal
"Å" == "Å" => true and false?
You can try this yourself in your favorite Unicode-supporting programming language. The below example's lines can be entered into your browser's JavaScript REPL (F12 -> Console on most browsers):
// Both escaped sequences appear the same...
"\u00C5" // => "Å"
"A\u030A" // => "Å"
// But do not test the same.
"\u00C5" == "A\u030A" // => false
"Å" == "Å" // => false (same as above)
"Å" == "Å" // => true
Huh??? How does "Å" == "Å" evaluate to both true and false?
In the first case "Å" == "Å", we're not really comparing the same character; we're comparing two forms of the same character "Å": the NFC form and the NFD form.
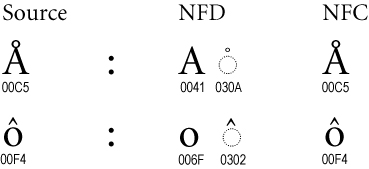
Source: http://unicode.org/reports/tr15/#Canonical_Composites_Figure
Another NFC vs NFD example
| NFC character | A | m | é | l | i | e | |
|---|---|---|---|---|---|---|---|
| NFC code point | 0041 | 006d | 00e9 | 006c | 0069 | 0065 | |
| NFD code point | 0041 | 006d | 0065 | 0301 | 006c | 0069 | 0065 |
| NFD character | A | m | e | ◌́ | l | i | e |
It's important to note that both forms represent the same character semantically. Their code points are different, but for all intents and purposes, the characters they represent are the same.
Programming languages that come with Unicode support usually have Unicode normalization methods.
function doesAccountExist(username) {
// The magic: normalize()
var nfcUsername = username.normalize("NFC");
return db.get("SELECT EXISTS (SELECT * FROM account WHERE username = ?)", nfcUsername)
.then(function(row) {
return row[0] != 0;
});
}
String lengths are weird
'Jörg'.length;
// => 4
'Jörg'.length;
// => 5
Yeah. Most programming languages determine a string's length by the number of codepoints it contains. If you haven't figured it out yet, the first Jörg is NFC and the second one is NFD.
Strings that appear the same could violate unique constraints
This is basically a rewording of the "Å" == "Å" problem.
SQL databases tend to highlight this issue with default collation settings. An example in SQLite:
CREATE TABLE account (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username VARCHAR UNIQUE
);
INSERT INTO account (username) VALUES ('sqlfan91');
-- Successful
INSERT INTO account (username) VALUES ('sqlfan91');
-- Error: UNIQUE constraint failed: account.username
INSERT INTO account (username) VALUES ('Jörg');
-- Successful
INSERT INTO account (username) VALUES ('Jörg');
-- Successful
-- We now have two Jörgs in our database. :(
SELECT * FROM account;
-- 1|sqlfan91
-- 2|Jörg
-- 3|Jörg
This issue tests positive in SQLite, MySQL, Oracle SQL, and likely most others.
Unfortunately, no SQL databases I know of have the option to auto-normalize inputted strings. If strings must meet unique constraints, then you'll likely need to normalize said strings at the application layer.
Note: Usernames on most web apps are traditionally restricted to alphanumeric characters for reasons such as this.
There's no such thing as a "universal sort" for strings
"Ö" comes before and after "U"?
Your favorite programming language probably has a list.sort() method. You've used it to sort a list of integers, and it works just fine. But what about strings?
Recall the SQL table from the previous section. Let's try ordering some data in it:
CREATE TABLE account (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username VARCHAR UNIQUE
);
INSERT INTO account (username) VALUES ('James'), ('Joe'), ('Josh'), ('Justin'), ('Jörg (NFC)'), ('Jörg (NFD)');
SELECT * FROM account ORDER BY username;
-- 1|James
-- 2|Joe
-- 3|Josh
-- 6|Jörg (NFD)
-- 4|Justin
-- 5|Jörg (NFC)
This behavior can also be seen in JavaScript:
['James', 'Joe', 'Josh', 'Justin', 'Jörg (NFC)', 'Jörg (NFD)'].sort()
// => ["James", "Joe", "Josh", "Jörg (NFD)", "Justin", "Jörg (NFC)"]
In the wacky world of Unicode, the letter "ö" (depending on its form) comes both before and after the letter "u". This is because in most programming languages, strings are simply sorted by each character's code points: numbers that map to a Unicode character.
In the NFC form, "ö" is U+00F6. In the NFD form, "ö" is U+006F, U+0308. In both NFC and NFD forms, "u" is U+0075.
Because 0x6F < 0x75, the NFD "ö" comes before "u", just like "o" does.
Because 0xF6 > 0x75, the NFC "ö" comes after "u".
Let's now assume that normalization is not an issue (all strings have been normalized to NFC). Vanilla sorts still may not be enough, depending on your use case. For locale-specific sorts, we need to talk about collations!
A collation specifies the natural ordering of characters in a language.
In German, the letter "ö" implicitly becomes "oe" when sorting names. That means the correct order should be:
INSERT INTO account (username) VALUES ('James'), ('Joe'), ('Josh'), ('Justin'), ('Jörg');
SELECT * FROM account ORDER BY username;
-- 1|James
-- 2|Joe
-- 5|Jörg
-- 3|Josh
-- 4|Justin
Fairly open and shut case, right? Not if you're Swedish. In Swedish, "ö" sorts at the end of the alphabet:
INSERT INTO account (username) VALUES ('James'), ('Joe'), ('Josh'), ('Justin'), ('Jörg');
SELECT * FROM account ORDER BY username;
-- 1|James
-- 2|Joe
-- 3|Josh
-- 4|Justin
-- 5|Jörg
Web frameworks do not normalize strings!
That's right - your favorite web framework probably doesn't auto-normalize your inputs, and neither do web browsers.
For developers hearing about this for the first time, this could open a whole new can of worms. Many of us, being native English speakers, assume that the world only operates on English characters. As such, we may not realize that our assumptions might be compromising the security of web applications.
If normalization is done haphazardly, someone could log in as both "Jörg" and "Jörg". There's certainly potential here for targeted phishing or backdoor attacks. In fact, Spotify has had this exact issue.
Unicode has multiple representations of English characters
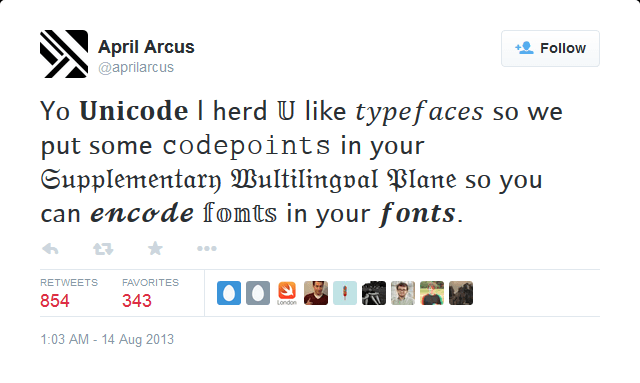
Source: https://twitter.com/aprilarcus/status/367557195186970624
There is not a single ASCII English letter in that tweet. Seriously, copy it into your favorite code editor. It's legit!
The way to extract the canonical characters from a string like this is with NFKC or NFKD normalization. Unlike NFC and NFD normalization, NFKC/NFKD will normalize characters that may look different, but are semantically the same as others.
"𝖸𝗈 𝐔𝐧𝐢𝐜𝐨𝐝𝐞 𝗅 𝗁𝖾𝗋𝖽 𝕌 𝗅𝗂𝗄𝖾 𝑡𝑦𝑝𝑒𝑓𝑎𝑐𝑒𝑠 𝗌𝗈 𝗐𝖾 𝗉𝗎𝗍 𝗌𝗈𝗆𝖾 𝚌𝚘𝚍𝚎𝚙𝚘𝚒𝚗𝚝𝚜 𝗂𝗇 𝗒𝗈𝗎𝗋 𝔖𝔲𝔭𝔭𝔩𝔢𝔪𝔢𝔫𝔱𝔞𝔯𝔶 𝔚𝔲𝔩𝔱𝔦𝔩𝔦𝔫𝔤𝔳𝔞𝔩 𝔓𝔩𝔞𝔫𝔢 𝗌𝗈 𝗒𝗈𝗎 𝖼𝖺𝗇 𝓮𝓷𝓬𝓸𝓭𝓮 𝕗𝕠𝕟𝕥𝕤 𝗂𝗇 𝗒𝗈𝗎𝗋 𝒇𝒐𝒏𝒕𝒔."
.normalize("NFKC");
// => "Yo Unicode l herd U like typefaces so we put some codepoints in your Supplementary Wultilingval Plane so you can encode fonts in your fonts."
Some humble advice
- Do normalize text that is cross-checked or visually compared, such as names.
- Do not normalize bodies of text, such as blog posts or status messages.
- Use UTF-8 when you have the choice.
- Use collations if non-English sorting is required.
- Fuzz test!
External links
- Unicode typeface tweet (works in Firefox): https://twitter.com/aprilarcus/status/367557195186970624
- Creative usernames and Spotify account hijacking: https://labs.spotify.com/2013/06/18/creative-usernames/
- I � Unicode: http://seriot.ch/resources/talks_papers/i_love_unicode_softshake.pdf